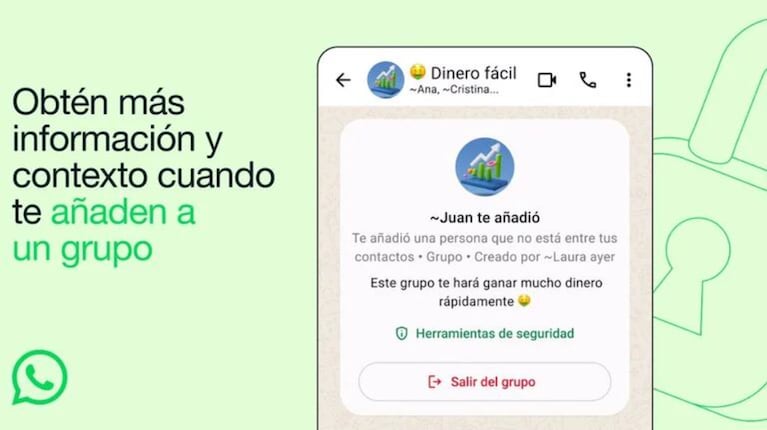
Amazon Web Services (AWS) está investigando el uso de Perplexity en sus servidores para determinar si la empresa utiliza ‘web scraping’ para entrenar sus modelos de IA.
Esta técnica implica extraer datos de páginas web mediante software que lee y guarda información del código HTML.
Según Wired y el desarrollador Robb Knight, Perplexity podría haber infringido el Protocolo de Exclusión de Robots al hacer esto.
PERPLEXITY ASEGURA RESPETAR EL ARCHIVO ROBOTS.TXT
Amazon Web Services (AWS) está investigando si Perplexity viola normas al usar ‘web scraping’ con sus servicios de IA, según informó Wired.
Un portavoz de AWS confirmó la investigación, destacando la prohibición de actividades ilegales en sus términos de servicio.

Perplexity asegura respetar el archivo robots.txt, pero admite excepciones en consultas de usuarios específicas.
PRÁCTICAS QUE CONFIRMAN LAS ACUSACIONES
La portavoz de Perplexity explicó que su ‘chatbot’ no activa el rastreo al ingresar una URL específica, comparándolo con copiar y pegar texto de un artículo.
Wired destacó que estas prácticas confirman las acusaciones de violación del robots.txt para recopilar datos sin autorización.
Fuente: EP.